👁 Бывает ситуация: сервис в Docker или Kubernetes начинает «лагать», но CPU, память и сеть по метрикам выглядят нормально. Проблема может быть в нестабильной сети — задержки, потери пакетов, джиттер. Чтобы воспроизвести и диагностировать такие кейсы, можно управлять сетью прямо на уровне ядра через tc.
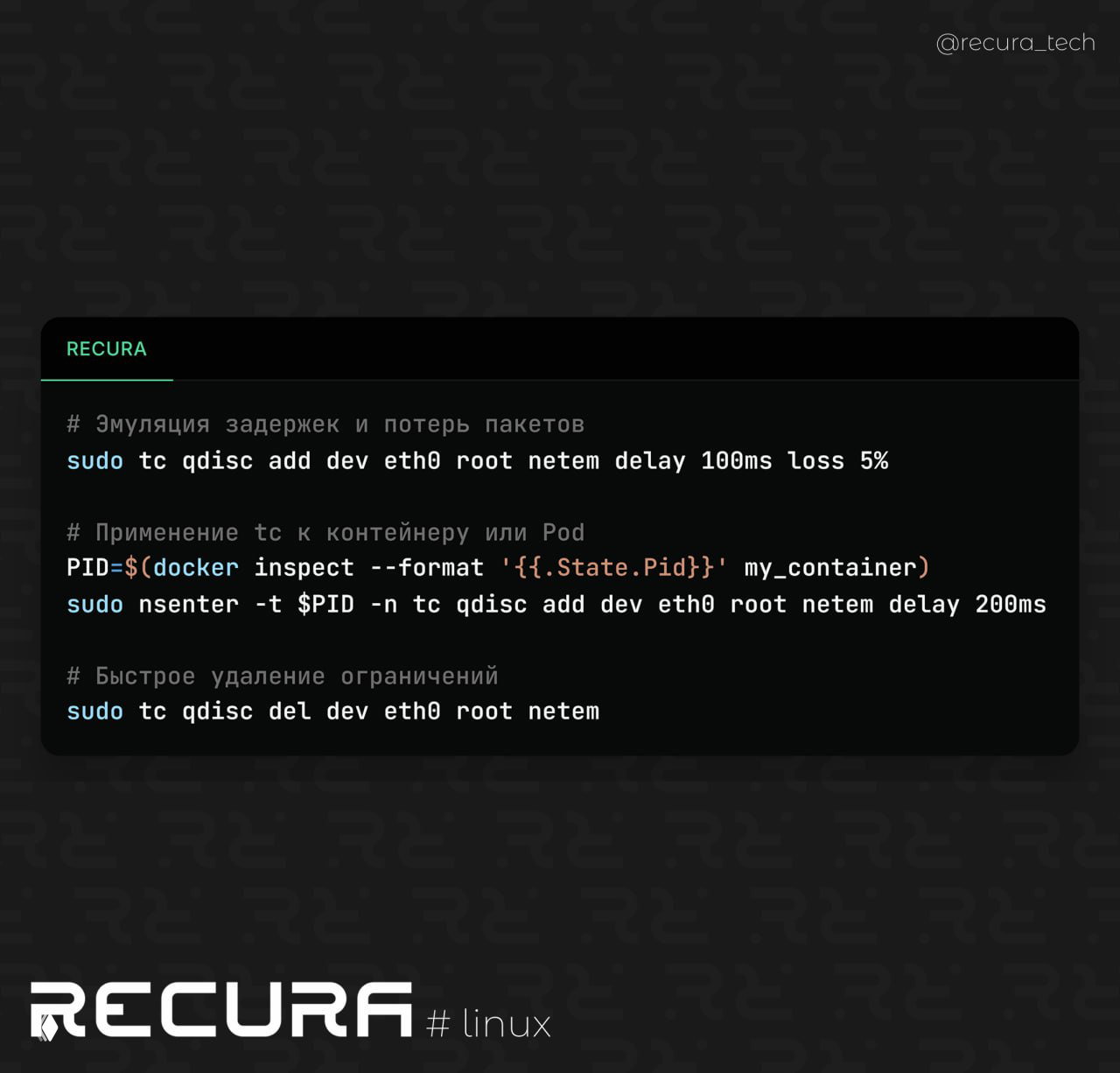
📝 Эмуляция задержек и потерь пакетов
С помощью tc netem можно добавить искусственные задержки и потери пакетов для интерфейса, чтобы воспроизвести продовые проблемы.
sudo tc qdisc add dev eth0 root netem delay 100ms loss 5%
📌 Теперь весь трафик будет идти с задержкой 100мс и 5% потерь — отличный способ проверить устойчивость сервиса и таймауты.
📝 Применение tc к контейнеру или Pod
Если нужно тестировать конкретный контейнер, можно применить настройки к его network namespace. Это позволит влиять только на конкретный контейнер, не затрагивая весь хост.
PID=$(docker inspect --format '{{.State.Pid}}' my_container)
sudo nsenter -t $PID -n tc qdisc add dev eth0 root netem delay 200ms
📝 Быстрое удаление ограничений
После тестирования важно вернуть всё обратно, иначе можно словить странные баги. Это полностью убирает все сетевые ограничения.
sudo tc qdisc del dev eth0 root netem
❗️ Такой подход позволяет не просто «дебажить сеть», а воспроизводить реальные продовые проблемы: задержки, деградацию, нестабильность. Это критично для сервисов с API, очередями и микросервисной архитектурой.
tags: #linux #сети #полезно